Controller 原理
在 Kubernetes 中,用户通过 声明式 API 定义资源的 “预期状态”,Controller 则负责监视资源的实际状态,当资源的实际状态和“预期状态”不一致时,Controller 则对系统进行必要的更改,以确保两者一致,这个过程被称之为 调谐(Reconcile)。
K8s的 Controller Manager 包含多种类型的 Controller,例如 Deployment Controller、ReplicaSet Controller 和 StatefulSet Controller 等。每个控制器都有不同的工作原理和适用场景,但它们的基本原理都是相同的。我们也可以根据需要编写 Controller 来实现自定义的业务逻辑。
K8s HTTP API 的 List Watch 机制
Controller 工作需要监控 K8s 中资源的状态,这是如何实现的呢?
K8s API Server 提供了获取某类资源集合的 HTTP API,此类 API 被称为 List 接口。例如下面的 URL 可以列出 default namespace 下面的 Pod。
HTTP GET api/v1/namespaces/default/pods
在该 URL 后面加上参数 ?watch=true,则 API Server 会对 default namespace 下面的 pod 的状态进行持续监控,并在 pod 状态发生变化时通过 chunked Response (HTTP 1.1) 或者 Server Push(HTTP2) 通知到客户端。K8s 称此机制为 watch。
HTTP GET api/v1/namespaces/default/pods?watch=true
Watch 返回的 Response 中有三种类型的事件:ADDED ,MODIFIED 和 DELETED。 ADDED 表示创建了新的 Pod,Pod 的状态变化会产生 MODIFIED 类型的事件,DELETED 则表示 Pod 被删除。
Informer 机制
为方便用户开发,K8s提供了 client-go 封装了上述逻辑,目前 client-go 已经被单独抽取出来成为一个项目了,除了在 kubernetes 中经常被用到,在 kubernetes 的二次开发过程中会经常用到 client-go,比如可以通过 client-go 开发自定义 Controller。
client-go 包中一个非常核心的工具就是 Informer,Informer 可以让与 kube-apiserver 的交互更加优雅。
Informer 主要功能可以概括为两点:
- 资源数据缓存功能,缓解对
kube-apiserver的访问压力 - 资源事件分发,触发事先注册好的
ResourceEventHandler
在 Kubernetes 中,Informer 是一个客户端库,用于监视 Kubernetes API 服务器中的资源并将它们的当前状态缓存到本地。Informer 提供了一种方法,让客户端应用程序可以高效地监视资源的更改,而无需不断地向 API 服务器发出请求。
Informer 另外一块内容在于提供了事件 handler 机制,并会触发回调,这样 Controller 就可以基于回调处理具体业务逻辑。因为 Informer 通过 List、Watch 机制可以监控到所有资源的所有事件,因此只要给 Informer 添加 ResourceEventHandler 实例的回调函数实例取实现 OnAdd、 OnUpdate 和 OnDelete 这三个方法,就可以处理好资源的创建、更新和删除操作。
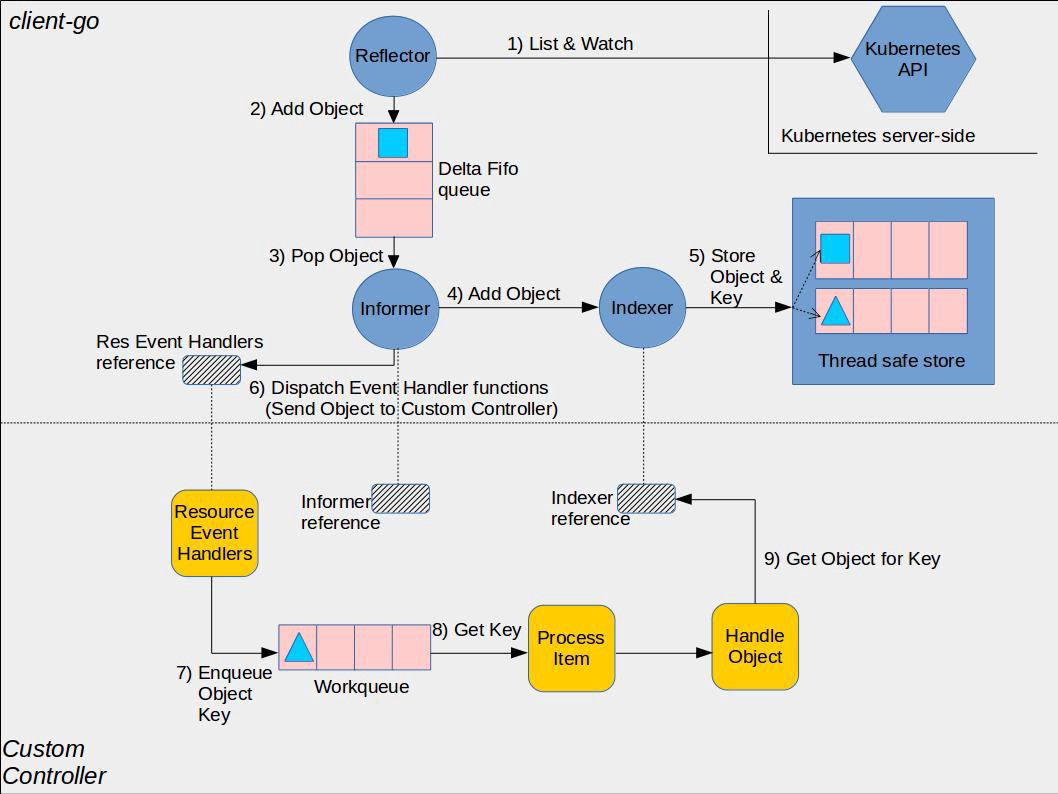
采用 Informer 库编写的 Controller 的架构如下图所示:
// see file: k8s.io/client-go/examples/workqueue/main.go:
package main
import (
...
)
// Controller demonstrates how to implement a controller with client-go.
type Controller struct {
indexer cache.Indexer
queue workqueue.RateLimitingInterface
informer cache.Controller
}
// NewController creates a new Controller.
func NewController(queue workqueue.RateLimitingInterface, indexer cache.Indexer, informer cache.Controller) *Controller {
return &Controller{
informer: informer,
indexer: indexer,
queue: queue,
}
}
func (c *Controller) processNextItem() bool {
// Wait until there is a new item in the working queue
key, quit := c.queue.Get()
if quit {
return false
}
// Tell the queue that we are done with processing this key. This unblocks the key for other workers
// This allows safe parallel processing because two pods with the same key are never processed in
// parallel.
defer c.queue.Done(key)
// Invoke the method containing the business logic
err := c.syncToStdout(key.(string))
// Handle the error if something went wrong during the execution of the business logic
c.handleErr(err, key)
return true
}
// syncToStdout is the business logic of the controller. In this controller it simply prints
// information about the pod to stdout. In case an error happened, it has to simply return the error.
// The retry logic should not be part of the business logic.
func (c *Controller) syncToStdout(key string) error {
obj, exists, err := c.indexer.GetByKey(key)
if err != nil {
klog.Errorf("Fetching object with key %s from store failed with %v", key, err)
return err
}
if !exists {
// Below we will warm up our cache with a Pod, so that we will see a delete for one pod
fmt.Printf("Pod %s does not exist anymore\n", key)
} else {
// Note that you also have to check the uid if you have a local controlled resource, which
// is dependent on the actual instance, to detect that a Pod was recreated with the same name
fmt.Printf("Sync/Add/Update for Pod %s\n", obj.(*v1.Pod).GetName())
}
return nil
}
// handleErr checks if an error happened and makes sure we will retry later.
func (c *Controller) handleErr(err error, key interface{}) {
if err == nil {
// Forget about the #AddRateLimited history of the key on every successful synchronization.
// This ensures that future processing of updates for this key is not delayed because of
// an outdated error history.
c.queue.Forget(key)
return
}
// This controller retries 5 times if something goes wrong. After that, it stops trying.
if c.queue.NumRequeues(key) < 5 {
klog.Infof("Error syncing pod %v: %v", key, err)
// Re-enqueue the key rate limited. Based on the rate limiter on the
// queue and the re-enqueue history, the key will be processed later again.
c.queue.AddRateLimited(key)
return
}
c.queue.Forget(key)
// Report to an external entity that, even after several retries, we could not successfully process this key
runtime.HandleError(err)
klog.Infof("Dropping pod %q out of the queue: %v", key, err)
}
// Run begins watching and syncing.
func (c *Controller) Run(workers int, stopCh chan struct{}) {
defer runtime.HandleCrash()
// Let the workers stop when we are done
defer c.queue.ShutDown()
klog.Info("Starting Pod controller")
go c.informer.Run(stopCh)
// Wait for all involved caches to be synced, before processing items from the queue is started
if !cache.WaitForCacheSync(stopCh, c.informer.HasSynced) {
runtime.HandleError(fmt.Errorf("Timed out waiting for caches to sync"))
return
}
for i := 0; i < workers; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
<-stopCh
klog.Info("Stopping Pod controller")
}
func (c *Controller) runWorker() {
for c.processNextItem() {
}
}
func main() {
var kubeconfig string
var master string
flag.StringVar(&kubeconfig, "kubeconfig", "", "absolute path to the kubeconfig file")
flag.StringVar(&master, "master", "", "master url")
flag.Parse()
// creates the connection
config, err := clientcmd.BuildConfigFromFlags(master, kubeconfig)
if err != nil {
klog.Fatal(err)
}
// creates the clientset
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
klog.Fatal(err)
}
// create the pod watcher
podListWatcher := cache.NewListWatchFromClient(clientset.CoreV1().RESTClient(), "pods", v1.NamespaceDefault, fields.Everything())
// create the workqueue
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
// Bind the workqueue to a cache with the help of an informer. This way we make sure that
// whenever the cache is updated, the pod key is added to the workqueue.
// Note that when we finally process the item from the workqueue, we might see a newer version
// of the Pod than the version which was responsible for triggering the update.
indexer, informer := cache.NewIndexerInformer(podListWatcher, &v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
UpdateFunc: func(old interface{}, new interface{}) {
key, err := cache.MetaNamespaceKeyFunc(new)
if err == nil {
queue.Add(key)
}
},
DeleteFunc: func(obj interface{}) {
// IndexerInformer uses a delta queue, therefore for deletes we have to use this
// key function.
key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
}, cache.Indexers{})
controller := NewController(queue, indexer, informer)
// Now let's start the controller
stop := make(chan struct{})
defer close(stop)
go controller.Run(1, stop)
// Wait forever
select {}
}
在 controller.Run 方法中:
- 先调用
informer.Run(stopCh),该方法会调用 Reflector 的ListAndWatch方法。ListAndWatch首先采用HTTP List API从 K8s API Server 获取当前的资源列表,然后调用HTTP Watch API对资源变化进行监控,并把List和Watch的收到的资源通过ResourceEventHandlerFuncs的AddFunc、UpdateFunc、DeleteFunc三个回调接口分发给Controller。 - 然后调用
cache.WaitForCacheSync(stopCh, c.informer.HasSynced),从方法名可直观的了解到该方法是为了确保Informer的本地缓存已经和 K8s API Server 的资源数据进行了同步。当 Reflector 成功调用ListAndWatch方法从 K8s API Server 获取到需要监控的资源数据并保存到本地缓存后,会将c.informer.HasSynced设置为true。在开始业务处理前调用该方法可以确保在本地缓存中的资源数据是和 K8s API Server 中的数据一致的。
SharedInformer
如果在一个应用中有多处相互独立的业务逻辑都需要监控同一种资源对象,用户会编写多个 Informer 来进行处理。这会导致应用中发起对 K8s API Server 同一资源的多次 ListAndWatch 调用,并且每一个 Informer 中都有一份单独的本地缓存,增加了内存占用。
K8s 在 client-go 中基于 Informer 之上再做了一层封装,提供了 SharedInformer 机制。采用 SharedInformer 后,客户端对同一种资源对象只会有一个对 API Server 的 ListAndWatch 调用,多个 Informer 也会共用同一份缓存,减少了对 API Server 的请求,提高了性能。
SharedInformerFactory 中有一个 Informer Map。当应用代码调用 InformerFactory 获取某一资源类型的 Informer 时, SharedInformer 会判断该类型的 Informer 是否存在,如果不存在就新建一个 Informer 并保存到该 Map 中,如果已存在则直接返回该 Informer(参见 SharedInformerFactory 的 InformerFor 方法)。因此应用中所有从 InformerFactory 中取出的同一类型的 Informer 都是同一个实例。
使用 SharedInformer 重写上面的代码:
...
func main() {
var kubeconfig string
var master string
flag.StringVar(&kubeconfig, "kubeconfig", "", "absolute path to the kubeconfig file")
flag.StringVar(&master, "master", "", "master url")
flag.Parse()
// creates the connection
config, err := clientcmd.BuildConfigFromFlags(master, kubeconfig)
if err != nil {
klog.Fatal(err)
}
// creates the clientset
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
klog.Fatal(err)
}
// create an informer factory
informerFactory := informers.NewSharedInformerFactory(clientset, time.Second*30)
// create an informer and lister for pods
informer := informerFactory.Core().V1().Pods()
// create the workqueue
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
// register the event handler with the informer
indexer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
UpdateFunc: func(old interface{}, new interface{}) {
key, err := cache.MetaNamespaceKeyFunc(new)
if err == nil {
queue.Add(key)
}
},
DeleteFunc: func(obj interface{}) {
// IndexerInformer uses a delta queue, therefore for deletes we have to use this
// key function.
key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
}, cache.Indexers{})
controller := NewController(queue, informer.Lister(), informer.Informer())
// Now let's start the controller
stop := make(chan struct{})
defer close(stop)
informerFactory.Start(stop)
go controller.Run(1, stop)
// Wait forever
select {}
}
Leader Election
在实际部署时,为了保证 Controller 的高可用,通常会运行多个 Controller 实例。在这种情况下,多个 Controller 实例之间需要进行 Leader Election。被选中成为 Leader 的 Controller 实例才执行 Watch 和 Reconcile 逻辑,其余 Controller 处于等待状态。当 Leader 出现问题后,另一个实例会被重新选为 Leader,接替原 Leader 继续执行。
具体实现是,Kubernetes 为 Controller 的 Leader Election 创建一个 Lease 对象,该对象 spec 中的 holderIdentity 是当前的 Leader,一般会使用 Leader 的 pod name 作为 Identity。leaseDurationSeconds 是锁的租赁时间,renewTime 则是上一次的更新时间。参与选举的实例会判断当前是否存在该 Lease 对象,如果不存在,则会创建一个 Lease 对象,并将 holderIdentity 设为自己,成为 Leader 并执行调谐逻辑。其他实例则会定期检测该 Lease 对象,如果发现租赁过期,则会试图将 holderIdentity 设为自己,成为新的 Leader。
// we use the Lease lock type since edits to Leases are less common
// and fewer objects in the cluster watch "all Leases".
lock := &resourcelock.LeaseLock{
LeaseMeta: metav1.ObjectMeta{
Name: leaseLockName,
Namespace: leaseLockNamespace,
},
Client: client.CoordinationV1(),
LockConfig: resourcelock.ResourceLockConfig{
Identity: id,
},
}
// start the leader election code loop
leaderelection.RunOrDie(ctx, leaderelection.LeaderElectionConfig{
Lock: lock,
// IMPORTANT: you MUST ensure that any code you have that
// is protected by the lease must terminate **before**
// you call cancel. Otherwise, you could have a background
// loop still running and another process could
// get elected before your background loop finished, violating
// the stated goal of the lease.
ReleaseOnCancel: true,
LeaseDuration: 60 * time.Second,
RenewDeadline: 15 * time.Second,
RetryPeriod: 5 * time.Second,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
// we're notified when we start - this is where you would
// usually put your code
run(ctx)
},
OnStoppedLeading: func() {
// we can do cleanup here
klog.Infof("leader lost: %s", id)
os.Exit(0)
},
OnNewLeader: func(identity string) {
// we're notified when new leader elected
if identity == id {
// I just got the lock
return
}
klog.Infof("new leader elected: %s", identity)
},
},
})